
AI基盤のネットワーク構築では、長らく「InfiniBand」が定番とされてきました 。しかし、本当にそれが唯一の解なのでしょうか。
その常識を問うべく、私たちの身近なEthernetの実力を、基礎的な通信テストから実践的な分散学習まで段階的に徹底検証しました。
GPUサーバー2台の構成において、単体での実行に比べ処理時間を44%も短縮できるという結果が得られました。
性能の最適解を求める方必見のレポートです。
今、空前の「AIブーム」が巻き起こり、多くの企業がその活用に乗り出しています。
しかし、AI基盤の構築には「コストが高そう」「複雑でよくわからない」といった声も少なくありません。
特にAI基盤のネットワークインフラでは、長らく「InfiniBand」が定番とされてきました。
ところが、私たちの身近な「Ethernet」が、近年の技術革新によってAI環境でも十分な性能を発揮し始めています。
市場には情報が溢れていますが、「自社の環境ではどうか?」「実際に試すとどうなるのか?」という疑問への答えは、なかなか見つかりません。
私たちの身近な「Ethernet」は、AI基盤のネットワークとして十分な性能を発揮できるのか。 その答えを求めた私たちの検証は、Ethernetが持つ大きな可能性を示す結果となりました。
今回、基礎的な通信テストからGPU間のベンチマーク、そして実践的な機械学習の動作まで、段階的に性能を評価しました。
そのハイライトとなる分散学習では、2台のサーバーを利用することで、単体での学習と比べて処理時間を44%も短縮できたのです。
本記事では、これらの検証の全貌を、包み隠さずご紹介します。
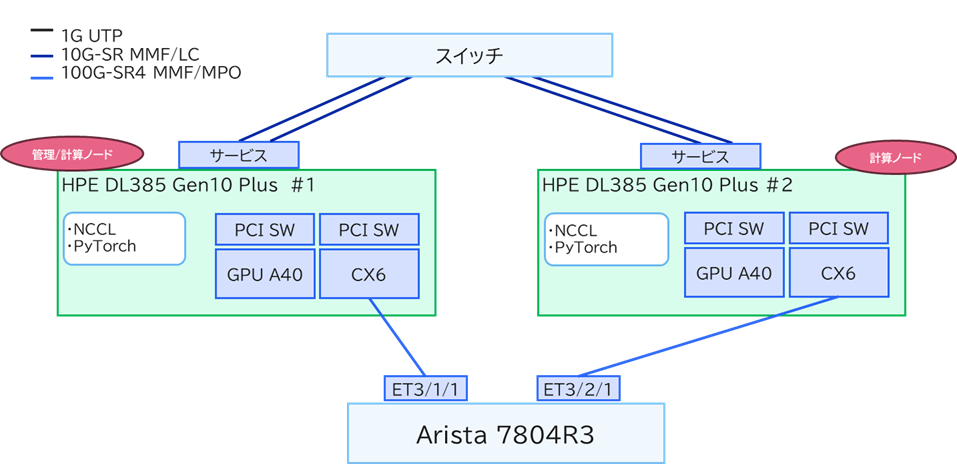
検証環境
検証で利用した機器は以下の通りです。

検証環境構成図
2台のGPUサーバーを、100GbEのEthernetスイッチを介して接続したシンプルな構成です 。
(管理ノード: リソース管理やジョブの割り当てを行う 、計算ノード: 計算処理を行う)
私たちの検証は、大きく3つのステップで進めました。
- 動作確認
- スループット測定
- GPU-GPU間の通信性能/計算能力の評価
動作確認
まず、サーバー同士が高速通信技術「RDMA」※1で正しく会話できるか確認しました。
以下実行結果になります。
RDMA版のpingとも言える「rping」コマンドを実行すると、正常に完了し、2サーバー間でRDMA通信が確立されていることを確認しました。
|
<サーバー①> ※サーバーとして実行 ai-ubuntu01:~$ rping -s -a 192.168.1.1 -vrping -s -a 192.168.1.1 -v server ping data: rdma-ping-0: ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr server ping data: rdma-ping-1: BCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs server ping data: rdma-ping-2: CDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst server ping data: rdma-ping-3: DEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstu server ping data: rdma-ping-4: EFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuv server ping data: rdma-ping-5: FGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvw server ping data: rdma-ping-6: GHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwx server ping data: rdma-ping-7: HIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxy server ping data: rdma-ping-8: IJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz server ping data: rdma-ping-9: JKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzA server ping data: rdma-ping-10: KLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzA --snip-- server ping data: rdma-ping-16: QRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFG server ping data: rdma-ping-17: RSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGH server ping data: rdma-ping-18: STUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGHI server ping data: rdma-ping-19: TUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGHIJ server DISCONNECT EVENT... wait for RDMA_READ_ADV state 10 |
|
<サーバー②> ※クライアントとして実行 ai-ubuntu02:~$ rping -c -a 192.168.1.1 -C 20 -vrping -c -a 192.168.1.1 -C 20 -v ping data: rdma-ping-0: ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqr ping data: rdma-ping-1: BCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrs ping data: rdma-ping-2: CDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrst ping data: rdma-ping-3: DEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstu ping data: rdma-ping-4: EFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuv ping data: rdma-ping-5: FGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvw ping data: rdma-ping-6: GHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwx ping data: rdma-ping-7: HIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxy
ping data: rdma-ping-14: OPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDE ping data: rdma-ping-15: PQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEF ping data: rdma-ping-16: QRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFG ping data: rdma-ping-17: RSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGH ping data: rdma-ping-18: STUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGHI ping data: rdma-ping-19: TUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyzABCDEFGHIJ client DISCONNECT EVENT... |
※1 RDMA(Remote Direct Memory Access): CPUを介さず、サーバー間で直接メモリ上のデータを読み書きする技術です。
スループット測定
次に、このEthernet基盤の「基礎体力」を測定しました。一般的な「TCP通信」と、AI学習の鍵となる「RDMA通信」の性能を比べてみます 。
以下実行結果になります。
帯域幅でTCP通信の約5.8倍、通信の速さ(低遅延)も約60%向上と、そのポテンシャルの高さを示す結果が得られました。AI学習のように大量のデータをGPU間でやり取りする上で、この性能差が活きてくることが期待されます 。
■RDMAでの帯域幅、遅延の測定結果
|
ai-ubuntu02:~$ qperf ai-ubuntu@ai-ubuntu01:~$ qperf -cm1 -t 60 --use_bits_per_sec ai-ubuntu02-roce rc_bw rc_lat rc_bw: bw = 97.3 Gb/sec rc_lat: latency = 13.9 us |
■RDMA通信ではないTCPでの帯域幅、遅延の測定結果
|
ai-ubuntu01:~$ qperf ai-ubuntu02:~$ qperf -t 60 --use_bits_per_sec ai-ubuntu01-roce tcp_bw tcp_lat udp_bw udp_lat tcp_bw: bw = 16.9 Gb/sec tcp_lat: latency = 35.3 us udp_bw: send_bw = 21.5 Gb/sec recv_bw = 1.45 Gb/sec udp_lat: latency = 28.4 us |
GPU-GPU間の通信性能/計算能力の評価
GPU同士が連携する実践的なテストです。ここでは2段階で検証しました。
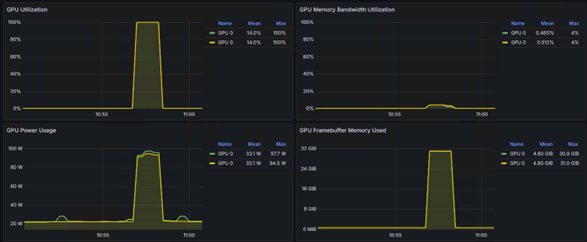
■ベンチマークでGPU間の対話速度チェック
NVIDIAが提供する「nccl-tests」という標準ベンチマークツールを使い、GPU同士がどれだけ高速に通信できるか、そのポテンシャルを最大限に引き出してみました。
以下実行時のGrafanaでの確認結果になります。
GPU使用率が100%に達し 、ネットワークも活発に利用されていることが確認できました。 これは、構築したEthernet基盤が、GPU間の高負荷な通信をしっかり支え、詰まることなくデータを流せている証拠です。
<サーバー側の結果>


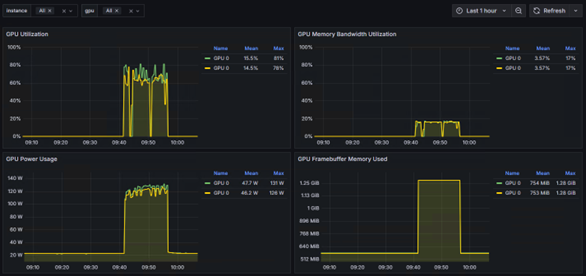
■実際のAI学習で効果を実証
画像認識モデル「ResNet18」を使い、実践的なデータセット「CIFAR-10」でファインチューニングを行いました。
以下実行時のGrafanaでの確認結果になります。
グラフが示す通り、分散学習中は2台のサーバーのGPUがしっかり連携して高い使用率を維持しており 、リソースを有効活用できていることが分かります。ベンチマーク通りの性能が、実際のAIアプリケーションの効率化に直接つながることを確認できました。
<サーバー側の結果>
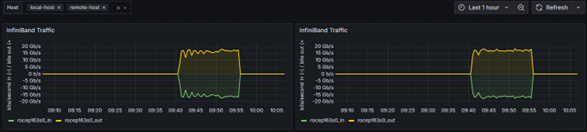
Grafanaの画面では、InfiniBand Trafficとあるが、この箇所でRoCE※2を利用していることを確認します。
※2 RoCE:Ethernetネットワーク上で低レイテンシ・高スループットなRDMA通信を可能にするプロトコルです。
<スイッチ側の結果>
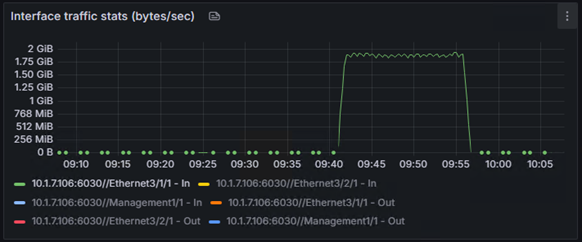
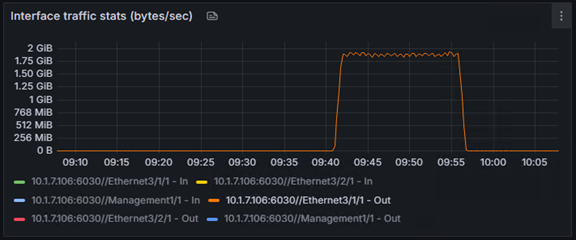
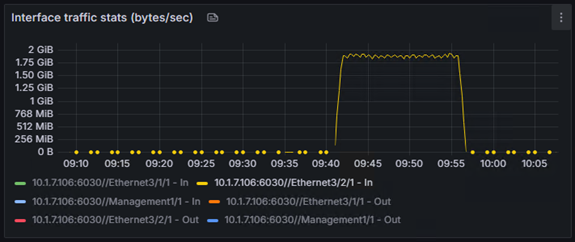
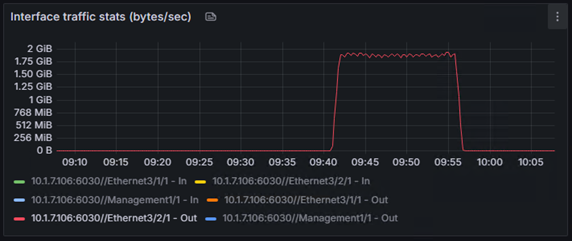
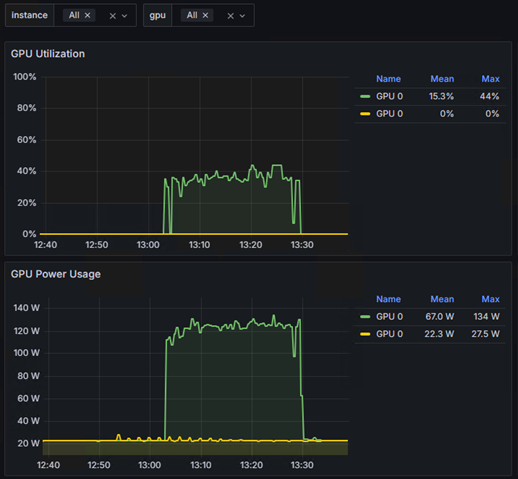
また、今回の検証のハイライトとして、単体(サーバー1台)での学習と、分散(サーバー2台)での学習で、どちらが速く完了するかも比較しました。
結果は、単体で約27分かかった学習は、分散することで約15分に。
これは、処理時間を44%も短縮できた計算になります。
以下は単体と分散のGPUの使用率です。
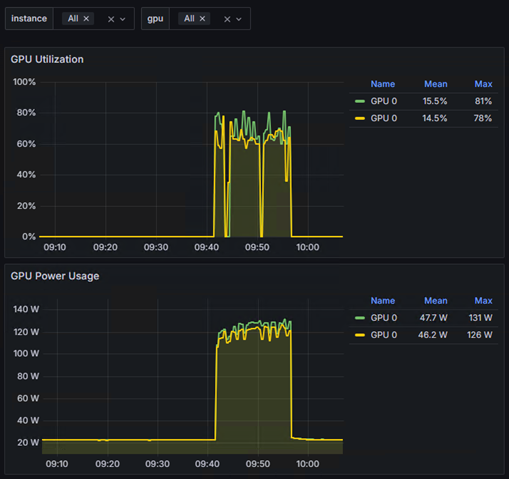
<単体>
今回の検証は、私たちにとってまさにゼロからのスタートでした。AI基盤という未知の領域へ、チームで手探りしながら踏み出した、等身大の挑戦。それが、この検証の原点です。
この検証プロセス全体が、私たちにとって最高の学びの場となりました。インフラとAI、両方のスキルを融合させることの重要性を実感しており、今後もこの分野の探求を続け、お客様により価値のある提案ができるよう努めてまいります。
双日テックイノベーションは、特定の製品に縛られることなく、常にお客様のビジネスにとっての最適解は何かを追求しています。そのために、机上の調査だけでなく、今回のような「泥臭い」とも言える実機検証を重ね、正直な結果と学びをお客様と共有していくこと。これこそが、私たちが最も大切にしている姿勢です。
AI基盤の構築や性能改善にご興味をお持ちの方はもちろん、「インフラだけでなくAIそのものについて話したい」「こんな検証を一緒にやってみたい」といったお声も大歓迎です。どんなことでも構いませんので、ぜひお気軽にご連絡ください。

工藤 央聖
アカウントSE、プロジェクトマネージャーを経て、現在はAIエンジニアとして活動。企業の課題解決に向けたAIソリューションの開発・提案に従事。







-
2026年7月1日 ものづくりワールド【東京】 2026 出展 登壇あり
- 2026年7月1日(水)~ 7月3日(金)10:00~17:00
- 東京ビッグサイト(西2ホール)
- ものづくりワールド【東京】製造業DX展 2026 出展 登壇あり
-
2026年3月26日 製造・倉庫DXの通信課題をROIで解く! ー Wi-Fi vs ローカル5G(Celona)実データと事例で徹底比較セミナー
- 2026/03/26(木) 13:00-14:00
- オンラインセミナー(ZOOM)
- 【03/26(木)13:00-14:00】製造・倉庫DXの通信課題をROIで解く! ー Wi-Fi vs ローカル5G(Celona)実データと事例で徹底比較セミナー
- 現場条件(ユースケース)をもとにCelonaとWi-FiのROIシミュレーション紹介 Wi-Fiを継続した場合 vs Celonaに切り替えた場合のコスト差・ROI比較を提示 DXを成功させるために通信の最適化は必須です。自社に合う無線は何か具体的に知りたい方、ご参加お待ちしてます。
- ローカル5Gプラットフォーム Celona(セロナ)
-
2025年11月5日 【11/05(水)13:00-14:00】製造・倉庫DXの通信課題をROIで解く!ー Wi-Fi vs ローカル5G(Celona)実データと事例で徹底比較セミナー
- 2025年11月05日(水)13:00-14:00
- Webセミナー
- 製造・倉庫DXの通信課題をROIで解く! ー Wi-Fi vs ローカル5G(Celona)実データと事例で徹底比較セミナー
-
2025年11月4日 COMNEXT 2025 ローカル5G「Celona」 出展 登壇あり
- 2025年7月30日(水)~ 8月1日(金)10:00~17:00
- 東京ビッグサイト(南展示棟)
- COMNEXT 2025 ローカル5G「Celona」 出展 登壇あり
- ローカル5GプラットフォームCelona(セロナ)

ProLabsは高品質かつ低価格のサードパーティ製光トランシーバーを提供いたします。業界標準規格品やベンダー互換品など豊富な製品ラインナップを揃えております。